APPENDIX B
AUDIO BUFFERS DON'T DO WHAT YOU THINK THEY DO!
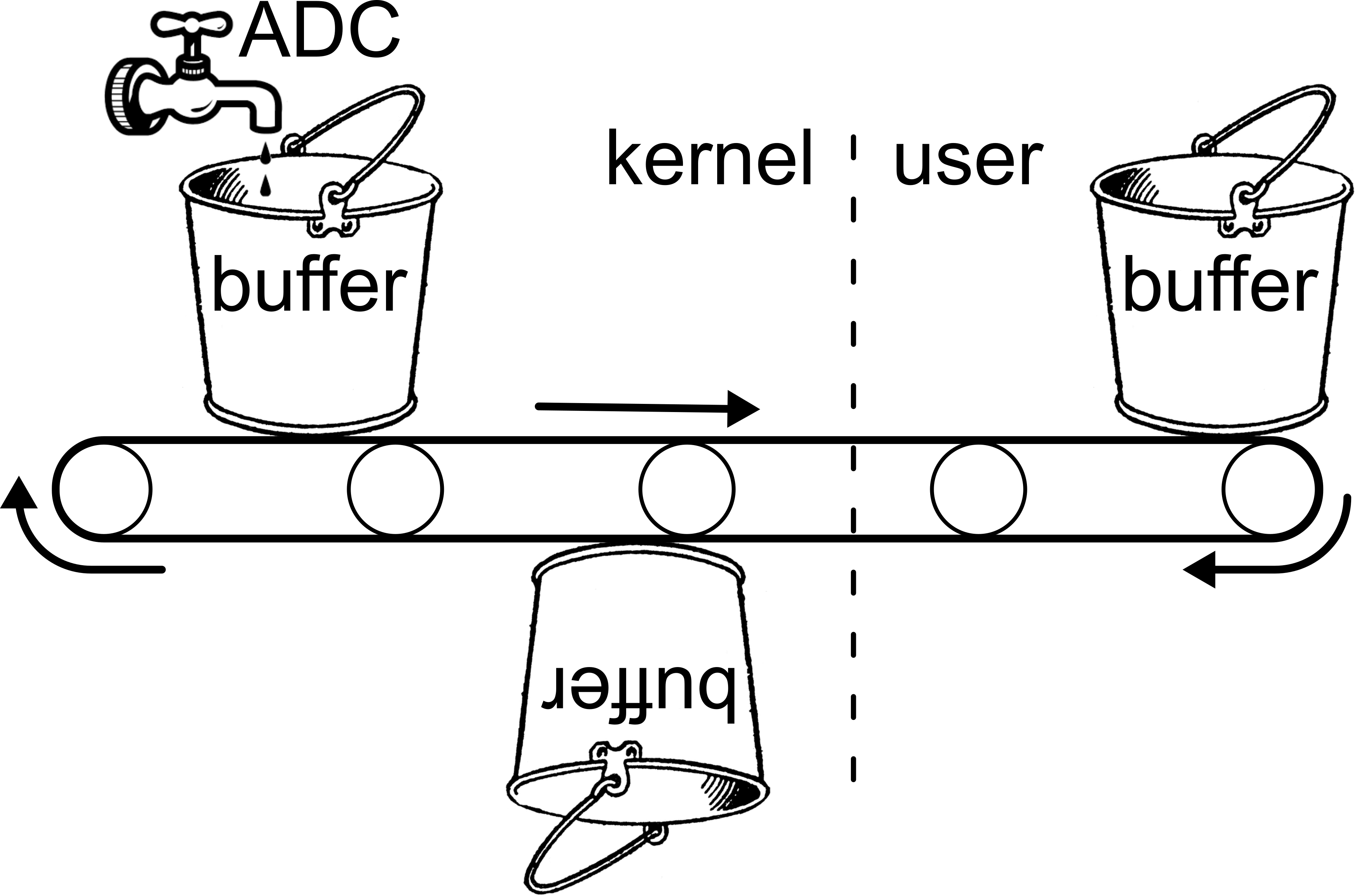
It is a universal misconception that, in audio systems, lhc_min (audio system input latency) can be reduced by reducing the user buffer size. This is based on the erroneous model of how audio samples are gathered and passed to userspace depicted in Figure 30.
In this model, the user allocates buffers of capacity n frames and passes them to the kernel. Incoming audio frames from the ADC are placed directly into an enqueued buffer, which is passed back to the user as soon as it becomes full. In this model, the user would receive buffers with a frequency of n/f where f is the audio frame rate. If n were 64 sample frames and f were 44.1 kHz, the user would expect a buffer every 1.5 milliseconds. This value is often wrongly taken to represent the system's buffering latency, and the uncertainty wrongly assumed to be on the order of 1/f or otherwise negligible.
Although this model is widely cited and even presented in the documentation for operating systems, it can be empirically demonstrated to be false (and will be momentarily). Simple analysis reveals the flaw in the above model. Namely, modern operating systems with kernels do not generally allow memory to be shared between userspace and the kernel, as this would largely defeat the purpose of the kernel, which is to protect the system's core functionality by isolating it. In fact, the ADC is typically a separate piece of hardware serviced by the DMA controller, and consequently audio samples are written directly to a special DMA area in RAM. The address of this DMA area cannot be specified by the user, nor can the user's buffers be allocated from this area, as attempting to access it would result in a segmentation fault. Clearly, audio samples must be written into a kernel buffer and subsequently copied into a userspace buffer. For operating systems where the source code is available, this is easily verified by inspecting the code. For example, in version 3.0.29 of the Linux Kernel, in the file /kernel/sound/core/lib_pcm.c, we find the function that is responsible for passing audio samples to userspace, simplified here for space and legibility:
snd_pcm_lib_read_transfer()
{
char __user *buf = (char __user *) data + offset;
char *hwbuf = runtime->dma_area + hwoffset;
copy_to_user(buf, hwbuf, frames);
}
The first two lines within this function calculate the memory addresses of the userspace and kernel buffers, respectively. The third line clearly shows audio samples being copied out of a DMA area owned by the kernel to a userspace buffer.
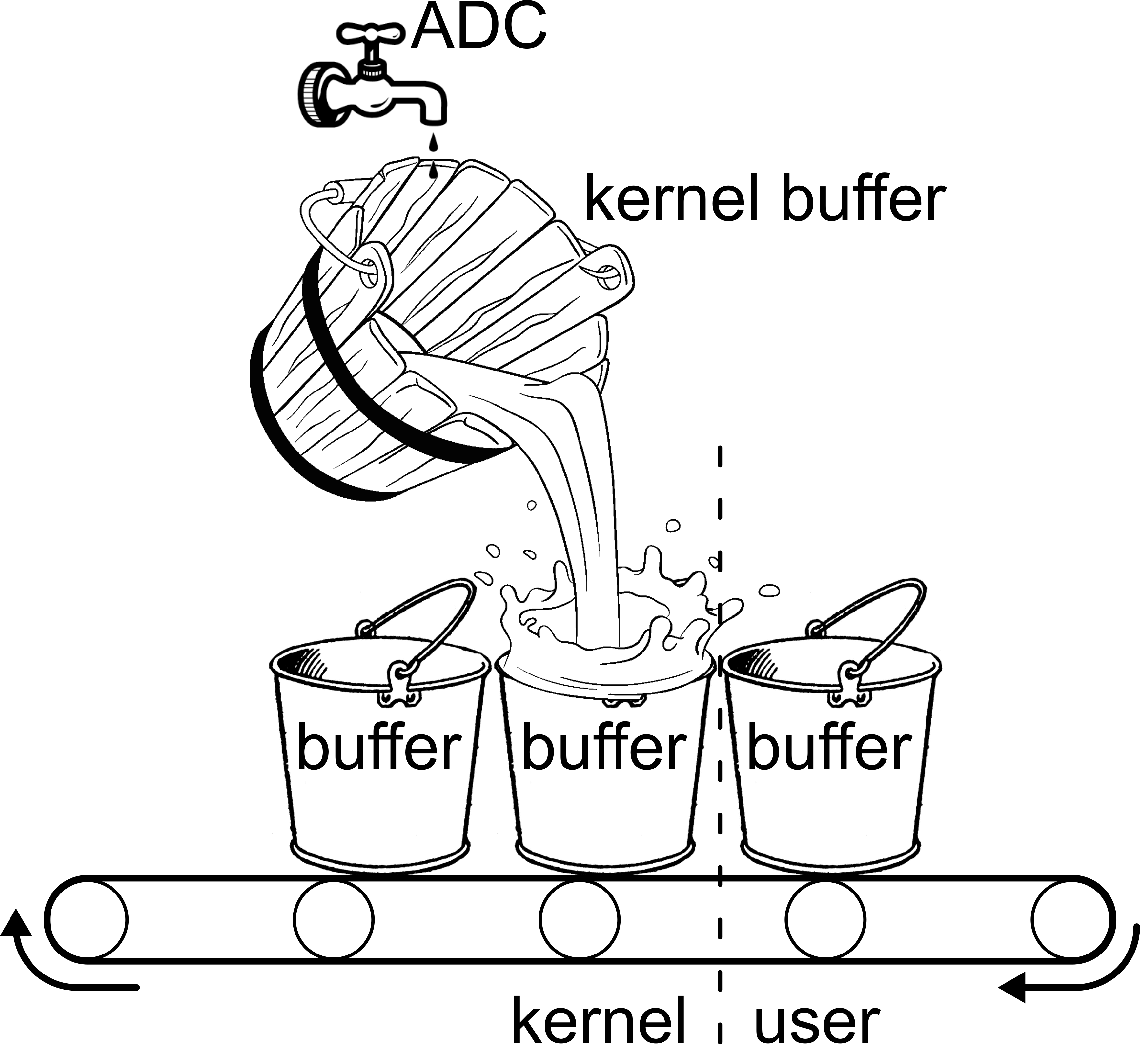
I therefore propose another hypothetical model which involves a kernel buffer that is separate from the userspace buffers. Additionally, we suppose for the sake of argument that the capacity of the kernel buffer might be much greater than a userspace buffer intended for realtime use. In this model, the user receives nothing until the kernel buffer is full. At that time, the kernel buffer is drained all at once by filling the user buffers and passing them to the user in rapid succession, each buffer being filled as soon as the previous one is enqueued. This model is shewn in Figure 31. In this model, if the kernel buffer has a capacity k of 4096 frames, and n and f are as above, the user will receive n/k = 64 buffers in rapid succession, and then nothing for about k/f=92.9 milliseconds (minus the time it took to process 64 buffers). Note that on average the user still must receive buffers with a frequency of n/f to prevent the kernel buffer from overflowing, but the uncertainty has skyrocketed to k/f. It is this latter value that must be included in the estimate of lhc_min.
A simple C-language program was written to test this hypothetical model on OS X. The software uses the native-language audio library (AudioToolbox version 1.12). It measures timing using mach_absolute_time(), which measures system up-time by counting clock cycles, and is more accurate than gettimeofday(), which may drift as the time daemon tries to synchronize with network time. The software registers a buffer callback function with the kernel, which the kernel calls every time it wants to pass a buffer of audio to the user. The callback function just measures the duration in microseconds since the previous time the callback was called. It also obtains the buffer timestamp from the kernel which indicates the time that the first sample in the buffer was acquired from the ADC; our software uses this to measure the latency between the first sample being acquired and the callback being called. We tested this with a variety of buffer sizes, number of buffers, number of channels, and sample rates. Representative results are displayed in Table 10.
| Buffer Number | μsec since prev callback | μsec since ADC |
| 40 | 92749 | 93350 |
| 41 | 58 | 81798 |
| 42 | 12 | 70200 |
| 43 | 10 | 58600 |
| 44 | 78 | 47068 |
| 45 | 42 | 35500 |
| 46 | 5 | 23895 |
| 47 | 3 | 12288 |
| 48 | 92641 | 93319 |
| 49 | 43 | 81752 |
| 50 | 4 | 70146 |
| 51 | 4 | 58540 |
| 52 | 28 | 46958 |
| 53 | 6 | 35354 |
| 54 | 4 | 23748 |
| 55 | 5 | 12143 |
This supports the hypothesis that the kernel stores an internal buffer of 4096 sample frames (92.9 milliseconds at 44.1 kHz) which is emptied according to out model. Similar tests supported the hypothesis that the size of this buffer, in frames, is constant regardless of user parameters. Notice that there is an additional constant latency of a little over half a millisecond, so that the last user buffer in a set is received about 0.5 ms after the last sample was acquired (based on the buffer start time and buffer duration). In any case, "sending a bang" or otherwise triggering an event at the moment the computer discovers an onset in the audio buffer will be a very inaccurate way of handling events. If a user needs to know what time an event in the audio stream occurred they may use the buffer's timestamp, if it has one, otherwise it is possible to count samples, although it may be difficult to ascertain what time the first sample occurred.
Although it is not important for the current study, a similar model can be demonstrated for output buffers. In this case, OSX was found to have an internal buffer size of 512 sample frames (11.6 milliseconds), as is supported by Table 11. Lowering the user buffer size below this has no effect on output latency.
| Buffer Number | μsec since previous callback |
| 1303 | 11492 |
| 1304 | 22 |
| 1305 | 6 |
| 1306 | 9 |
| 1307 | 11623 |
| 1308 | 23 |
| 1309 | 5 |
| 1310 | 3 |
| 1311 | 11608 |
| 1312 | 22 |
| 1313 | 4 |
| 1314 | 17 |