Explanation of the Concepts
"Granular Synthesis" is a technique that uses pre-recorded audio or other 'ready-made' sound to create new and often dense musical timbers that may or may not sound anything like the original audio. Consider the following audio signal:

For granular synthesis, an individual "grain" is extracted from the audio by first applying a special type of envelope, known as a "window function", to the amplitude of the pre-recorded audio. The window function must start and end at zero. It is typically bilaterally symmetrical. The duration of the window function is usually between about 0.05 and 1 second: In other words, it is slower than the audio-rate, but faster than (or on the order of) the smallest meaningful unit of, say, speech or music. Here, an "Hann" window function is drawn in red over the pre-recorded audio file.

Multiplying the window function by the pre-recorded audio results in the yellow line in the following image. (If you are not sure why they were multiplied, review the chapters on Basic Volume Control and Envelopes). Note that the resultant signal is just zero (silent) before and after the window function.

Trimming the silence results in the yellow line in the following image. This represents an audio signal that quickly fades in and back out. It is known as a "grain" (thus the term "granular" synthesis).
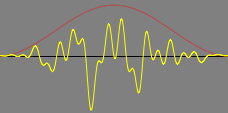
New sounds may then be created by juxtaposing, stacking and layering many individual grains beside and atop one another. In the following visual example, the above grain has been repeated several times, and each instance of the grain overlaps the previous grain by 50 percent.

The final audio signal (not shewn) would be the sum of all of these grains (review the chapter on Mixing/Playing Chords if this is not self-evident). In actual audio applications, each grain is usually unique. Individual grains may come from successive or random locations in the original audio file, or may even come from different audio files.